
Zeppelin is the ideal companion for any Spark installation. It is a notebook that allows you to perform interactive analytics on a web browser. You can execute Spark code and view the results in table or graph form. To find out more, follow the guide!

Installing Zeppelin
If, like me you have installed a stand-alone instance of Spark without hadoop, I recommend that you build Zeppelin from source code. However, for that you first need to install Maven.
To start the Zeppelin build with Spark1.5.2 execute this command:
mvn clean package -Pspark-1.5
Then you need to configure Zeppelin giving the parameters for a connection to your instance of Spark. Do this by editing files zeppelin-env.sh and zeppelin-site.xml which are located Zeppelin’s conf directory. For me, this gives:
Fragment of my zeppelin-env.sh
export MASTER=spark://spark.bd:7077 export SPARK_HOME=/root/spark_
Fragment of my zeppelin-site.xml
zeppelin.server.addr 0.0.0.0 Server address
zeppelin.server.port 8090 Server port.
Leave 0.0.0.0 as the server address Then specify your preferred port number.
Zeppelin can then be started. We start by launching Spark in cluster mode. start-master.sh start-slave.sh spark://spark.bd:7077 –m 2G
The slave must be launched with enough memory to execute Zeppelin. Otherwise you will be able to access your notebooks but you will not be able to execute Spark applications.
Then run Zeppelin. cd /root/incubator-zeppelin ./bin/zeppelin-daemon.sh start
You can check that Spark and Zeppelin have started up correctly by going to the Spark monitoring page (in my case, https://localhost:8080 )
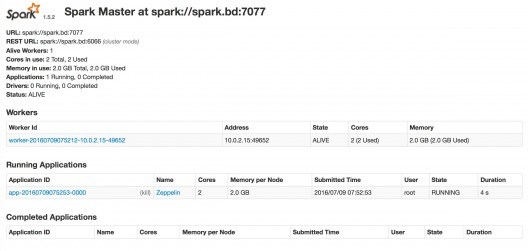
Presentation of Zeppelin
If all goes well, you will be able to access the Zeppelin home page at https://localhost:8090
You can open an existing notebook or create a notebook.
Spark application
The primary value of Zeppelin is being able to write Spark code. Note that the main libraries (spark, sparkContext) are imported automatically.
You can therefore write your code directly in a notebook window. Once you have entered the code, just click on the triangle at top right to execute it. The output will be displayed beneath the code.

Zeppelin offers the benefits of spark-shell (direct execution of the code without compilation) while showing all the lines of our application (so that they are easy to edit).
It is also not limited to the basic functions of Spark. For example, you can run machine learning algorithms by importing the required librairies at the beginning of the script.
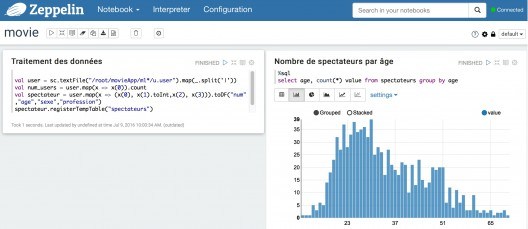
Graph view
If our application records data in DataFrames and then tables, we can then execute SQL code and display the results in the form of tables or graphs.
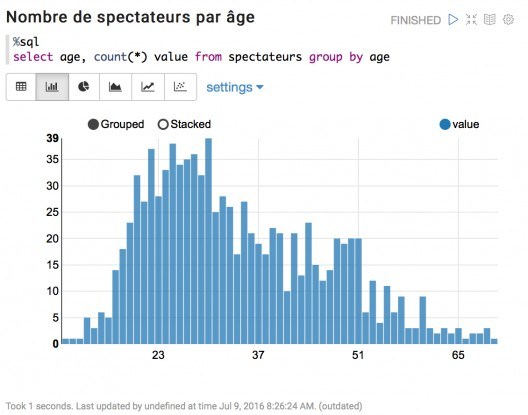
Of course, the options are limited: the aim of Zeppelin is not to compete with the big dogs of the sector like Qlik or Table. The benefit is that a single tool offers the ability to process data using Spark on a powerful cluster and to view the results.
Shell commands
Zeppelin also allows shell commands to be executed via the same interface. No need to open a terminal and connect to our Spark cluster. You can find the path to our files immediately or view the first few lines.
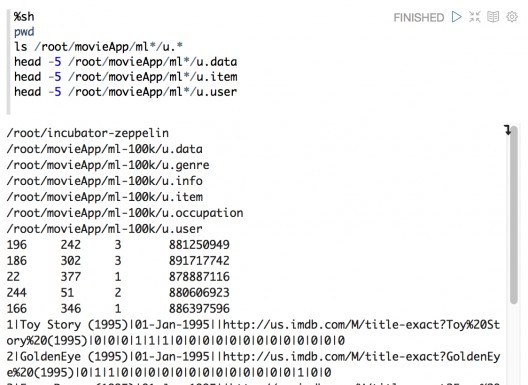
Settings
It is possible to configure the various windows of our notebook by clicking on the small cogwheel at top right.
You can then enter a title or reduce the width or our window.
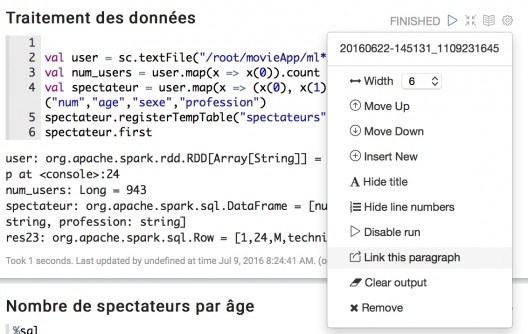
Here is an example of a two-column report with the code displayed and the application output masked:
Other functionalities
A notebook can be exported. It includes the code and the views if they have been generated but not the data: the file generated is thus very small.
It can be exported so that the notebook can be stored locally or sent to an email recipient who can import it to their own platform.
On an enterprise platform it is also possible to share a notebook by altering permissions, but I have not tested this.
Another interesting function: cloning, which lets you duplicate a notebook in order to make changes without risk.
A promising tool
Zeppelin is a promising tool. It answers a real need for an integrated took for all datalab type work using Spark. In incubation up to May this year, it has recently been lauded by the Apache community. As evidence of its success, it is already offered on the Hortonworks distribution. Find out more about it now by taking a look at the Apache project page.













Comment (1)
Your email address is only used by Business & Decision, the controller, to process your request and to send any Business & Decision communication related to your request only. Learn more about managing your data and your rights.