
Oil, digital black gold, strategic asset… With Data Mesh, data is regarded as a product. Data domains are responsible for managing the life cycle of these products and for sharing and promoting them throughout the organisation. This structuring into data products is the second of the four pillars of Data Mesh.
1- Data Mesh: the ultimate model for data-driven companies?
2- Data domains: Data Mesh gives business domains superpowers.
3- Data Mesh: data is a product
4- Data infrastructure self-service as the technological driving force behind Data Mesh
5- Data Mesh: federated governance to guarantee efficiency
Today, the most advanced companies are working on the concept of data products. They task entities such as their Data Factory, Data Office or their IT Department with building them.
Data Mesh goes further in generalising this concept, not only by distributing the creation of products across domains, but also by considering the data itself as a product and not only as a component of a larger digital product. By exposing only data products and providing the interfaces to access them, Data Mesh gives consumer domains the responsibility and freedom to analyse and render the data through application services that are best suited to their needs, taking into account the tools at their disposal.
With Data Mesh, data is the product
Note: Data Mesh distinguishes between the notions of data product and data as a product. A data product is defined as ‘a product that facilitates an end goal through the use of data’, i.e. the use of data in a digital product. The principle of data as a product, introduced by Data Mesh, is a subset of data products in which the data itself becomes the product. It therefore becomes the end and not just the means. In what follows, for the sake of simplicity, we will use the term ‘data product’ to refer to ‘data as a product’.
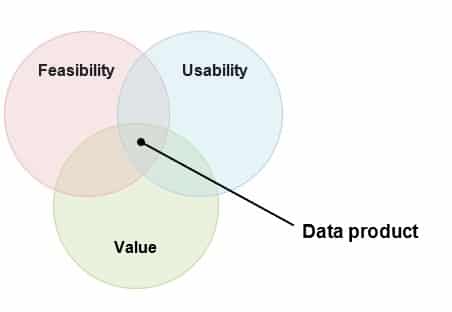
With Data Mesh, the data literally becomes the product, usually to be consumed in the form of a dataset. To be effective, data products must conform to a set of characteristics that place them at the intersection of usability, feasibility and value (Marty Cagan’s diagram).

The analogy with a bottle of water helps to further clarify the nature of this data as a product. In this metaphor, data is water. To be consumed, water requires a container, the bottle. For data, this will generally be a dataset.
However, it also mobilises marketing, compositional information, instructions for use, a display or sales area such as a supermarket shelf or an online retailer’s product page.
With Data Mesh, the data literally becomes the product, usually to be consumed in the form of a dataset.
In the Data Mesh theory: a product must meet six fundamental criteria
- Discoverable: the product is referenced in a data catalogue or marketplace and accompanied by a set of metadata to facilitate its exploration and identification by consumers at all stages of its life cycle.
- Addressable: to ensure productivity, each data product is located at a permanent and unique address, which guarantees the continuity of its use by the consumer domains irrespective of its evolution over time and in accordance with the access policy.
- Documented: the data is defined and documented by the domain within a federated catalogue to ensure clear and unambiguous understanding and interpretation by consumers (provenance, location, freshness of data, semantics, life cycle, data model, etc.).
- Reliable: the quality of the data is continuously measured and monitored by the producing domains (communication of quality indicators) to make the products reliable and to ensure a high level of user confidence.
- Interoperable: products are based on common standards, thereby facilitating their availability, reuse and cross-referencing, etc.
- Secure: as a strategic asset, the data is protected according to its level of sensitivity and authorisation (access rights, authentication, encryption, etc.).
To put it simply, a product generally consists of a dataset.
There are 5 main types of data product:
- Raw data, directly from a data source. Only a few basic processing or cleaning operations are carried out. The consumer domains are then entirely responsible for optimising the data provided.
- Derived data, which can be assimilated to raw data, enriched with complementary data on the basis of assembly and preparation work, carried out by the owner domain. The consumer domains are then entirely responsible for optimising the data provided.
- Data resulting from the processing of source data (raw or derived) by an algorithm (recommendation, scoring, classification or other algorithm) designed and implemented by the owner domain. Consumer domains remain in charge of its interpretation and final use.
- Decision support data, which is actionable analytical data resulting from potentially advanced processing. While the owner domain is responsible for the analysis of the data, the consumer domains remain in charge of its interpretation and end use.
- Automated decision support data is a similar type to the previous one, except that all intelligence, including interpretation and actionability, is placed under the responsibility of the owner domain, the consumer domains being, in this context, limited to the role of operator.
But to be completely accurate, a data product is the combination of a dataset, the associated governance, the means (process) necessary for its construction, its destination (analysis, communication, etc.) and its distribution packaging. It can also take the form of a data science algorithm, which, when made available as an API, can be queried by the domains. Inspired by the DevOps philosophy, a data product brings together the necessary data, code and infrastructure.
A product can also exploit other data products; indeed, this is recommended. A customer scoring algorithm provided by the e-commerce domain will, for example, exploit the ‘customer data’ product provided by marketing.
💡 5 main types of data product:
📌 Raw data
📌 Derived data
📌 Data resulting from the processing of source data by an algorithm
📌 Decision support data
📌 Automated decision support data
Moreover, in order to be consumable on a self-service basis, products need to be made available in standardised ways, primarily via APIs. Other forms of provision are also possible for specific needs (connectors, data visualisation tool, Data Science studio, etc.). The advantage of these channels is that they allow the use of authorisation management to control access to data.
Product management also requires the establishment of governance and standardisation rules and processes to promote its use throughout the company.

Building a data product: instructions and advantages
Beyond the six essential characteristics of the data product, the design of these products is based on operational activities. It is therefore necessary to choose the data sources, to document them, to detail the technical chain for making the data available (tools and methodologies, refresh rate, etc.) and its distribution methods.
Weather data, for example, can be disseminated in a wide variety of ways: time series, trend curves, algorithmic calculations, and so on. Each method of dissemination can be matched to different products. The same data can be disseminated in a variety of ways depending on its uses and users.
This approach has a number of advantages, including the standardisation of distribution methods, which allows domains to monitor consumption in detail and assess priority needs.
🔎 Amadeus & Data Mesh: hundreds of data products
As a provider of solutions for the travel industry (airlines and railway companies, airports, hotels, agencies, tour operators, etc.), Amadeus is committed to a Data Mesh approach. Yan Morvan (Cloud Data Platform principal engineer) and Damien Claveau (Data Platforms Operations lead engineer) gave an update on the progress of this approach at the Big Data & AI 2022 exhibition.
Amadeus therefore works in parallel on the four pillars: federated governance, automation of the data platform in the cloud, organisation into data domains, but also deployment of data products. The company thus offers its internal customers and partners hundreds of directly consumable data products. For example, BI reports on a company’s reservation lists aggregated according to multiple indicators.
To deliver the data products, Amadeus has implemented independent ‘application workspaces’ that are attached to an application or a development team. The workspaces contain the analytics services needed to transform the data. The applications in these spaces are connected to the various data stores in Data Mesh.
How do you implement the data product approach?
This pillar of Data Mesh can be demanding in terms of its implementation, as can division by domains. It implies a transformation of the organisation with a strong orientation towards agility at scale, whether in a Spotify– or SAFe-type variation. The implementation of such organisations, based on tribes or squads, requires a high level of employee involvement and a radical change in working methods.
While the digital and IT departments have learned to deploy these methodologies, businesses are not very familiar with them. However, adoption is intended to be gradual. Businesses can also rely on agile teams located in competence centres or dedicated departments.
The design and life cycle of products are supported by a key function, the Data Product Manager. Attached to a domain, his/her role will be to coordinate all the necessary activities for the product(s) for which he/she is responsible.
The design of a first product is the key initiation stage. It contributes to the transformation by introducing the principles of product road map and MVP (Minimum Viable Product), while promoting agility and its benefits. It encourages producers to prioritise and therefore identify those functions and products that create the most value.
The pilot product will ideally focus on a relevant use case, which will require access to multiple data sources, close to the business and considered complex to access in the company.
The creation of the product is an opportunity to acquire methodological and organisational skills. But to pursue agility, domains also need an IT platform and services that make it possible. This is the challenge of the third pillar of Data Mesh: the Self-Service Data Infrastructure as a Platform.
💡Things to remember
📌Six characteristics for data products: discoverable, addressable, documented, reliable, interoperable and secure
📌Availability standards (API, marketplace, etc.)
📌Gradual adoption of agility at scale
📌A key initiation approach: the design of the first product
📌Development and consumption facilitated by the platform
This article was written in collaboration with Christophe Auffray













Your email address is only used by Business & Decision, the controller, to process your request and to send any Business & Decision communication related to your request only. Learn more about managing your data and your rights.