
The CRISP methodology (originally known as CRISP-DM), first developed by IBM in the 60s for data mining projects, remains, today, the only truly efficient process used for Data Science projects…
CRISP methodology: User guide
The CRISP methodology includes 6 steps that range from business understanding to deployment and implementation.
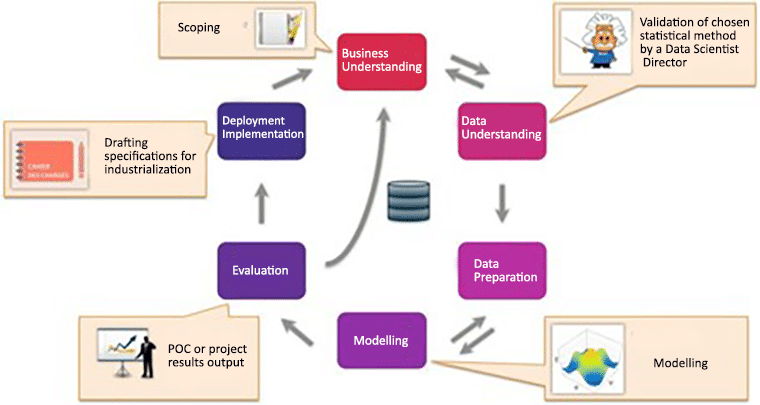
1. Business understanding
The first step involves acquiring a good understanding of the business elements and issues that Data Science aims to improve or solve.
2. Data understanding
The second step focuses on precisely identifying the data to be analysed, assessing the quality of available data and making connections in order to understand what the data means from a business point of view. Since Data Science is solely data-based, all business issues associated with existing data, whether internal or external, can be addressed through Data Science.
3. Data preparation
The data preparation step groups all activities required to construct, from raw data, a precise set of data to analyse. It thus includes data sorting based on selected criteria, data cleansing, and, most importantly, data recoding to ensure compatibility with any and all algorithms that will be used.
Digital data parametricity and its recoding into categorical data are extremely important and must be executed with the greatest care in order to ensure that used algorithms do not produce inaccurate results during the next step. All data must be centralised in a structured database known as a Data Hub.
4. Modelling
This is the actual Data Science step. Modelling includes selecting, configuring and testing various algorithms, as well as deciding on their sequence, which creates a model. The process is initially a descriptive one that generates knowledge and explains why things happened. It then becomes predictive and explains what will happen, and later prescriptive as it helps optimise future situations.
5. Evaluation
The aim of the evaluation step is to verify any models or knowledge obtained in order to ensure that they meet the objectives identified at the beginning of the process. The evaluation also informs model deployment decisions, or as required, model improvement ones. At this stage, the robustness and accuracy of developed models are tested.
6. Deployment
The final step of the process. It consists in implementing generated models for end users and its aim is to use modelling to format knowledge in such a way that it can be integrated into the decision-making process.
Depending on objectives, deployment can thus range from the simple generation of a report describing knowledge obtained to the installation of an application that helps leverage the obtained model to predict unknown values for an element of interest.
An agile and iterative approach
This is an agile and iterative methodology, i.e. each iteration generates additional business knowledge that helps improve the way the next iteration is handled. This is why, even though we market it as a project, Data Science is more of a global approach than a mere project.
The CRISP methodology has been officially adopted by Business & Decision, and is, without a doubt, a key success factor for Data Science projects.














Your email address is only used by Business & Decision, the controller, to process your request and to send any Business & Decision communication related to your request only. Learn more about managing your data and your rights.