
Automated machine learning (AutoML) has existed since 1990, it was considered as a silent revolution in the Artificial Intelligence (AI) field. When we analyze the term AutoML, we see that it refers to two words, Automated and Machine Learning.

Machine Learning with its different types of learning
- Supervised (Labeled data)
- Unsupervised (Unlabeled data)
- Semi-supervised (A mixture between labeled and unlabeled data)
- Reinforcement learning (learning from mistake)
AutoML aims to optimize and accelerate human tasks by improving everyday life. The list of examples could be very long, but I will mention a few: automatic waste classification, optimization of water filtering membranes maintenance, cyber security protocols improvement to detect attacks.
The “Auto” part refers to the automation algorithms of ML by using Machine Learning algorithms. In other words, we are taking the AI to another level, and that’s what leads the AutoML to become a hot topic in both Industry and Academia. However, the main question remains whether it is a real process or not.
The AutoML consists in optimizing all of the pipeline for a data science project. By this, we are referring to the Cross Industry Standard Process for Data Mining (CRISP-DM) methodology with the main phases: Business understanding, data understanding, data preparation, modeling, evaluation and deployment. This methodology defines the step by step guide of this project. Outside of the “business understanding” phase ,the AutoML aims to automate the whole pipeline in order to facilitate the task to a non-expert in this field (For instance Cloud AutoML by Google for the vision).
Some of the advantages of AutoML:
1. A good background for data preparation
Cleaning (filter noisy) and formatting (coded value like categorical) data needs a good background for data preparation. With the AutoML we can accelerate this phase by a process in which we have a different way to format and detect the noise in data.
2. Avoiding using the default parameters in the models
Because searching for the best parameters needs a knowledge of the Grid Search & Random Search methods (tuning techniques that attempts to compute the optimum values of hyperparameters) in order to give a list of settings and then choose the best ones. This whole process can be time consuming and that is why AutoML is needed to solve the problem.
3. Simplification to create and manage models
Usually, the data scientist make a list of the interesting models according to the context and to the problem. This requires a deep knowledge and a business expertise in the field of data. AutoML makes this step easier because it is a pipeline with more models to use for most problems.
4. Deep Learning (DL) Optimization
The Deep Learning is a function that imitates the human brain in processing data and creating patterns to be used in the decision making process. To do so, we have to look for the best architecture of neural network for the specific problem. For example, with Keras, an open source library for Deep Learning, we need a lot of lines of code to make the best architecture. However, thanks to the method Auto-Keras (library for DL) of Machine Learning, we are now able to obtain a better result with way less lines.
Automated Machine Learning Libraries:
To discover in depth the advantages mentioned above, here are some libraries of Auto-Machine Learning:
| The following phases | Use and source |
|---|---|
|
The Machine Learning Box (MLBox) |
|
Auto-sklearn
H2O Auto-ML |
|
TPOT stands for Tree-based Pipeline Optimization Tool |
| Auto-Keras Ludwig |
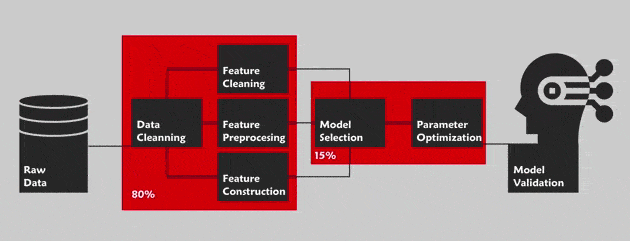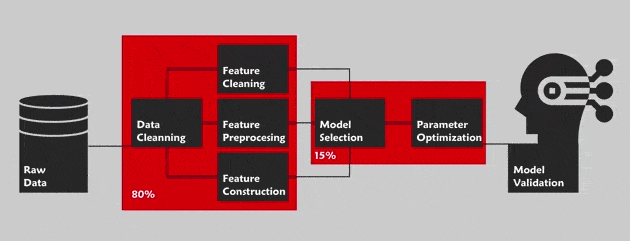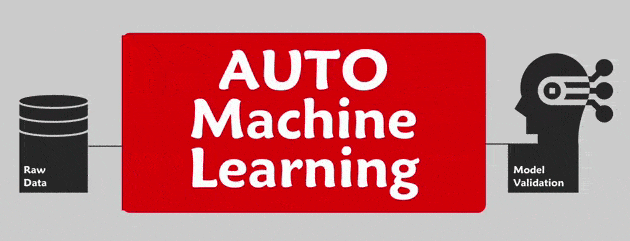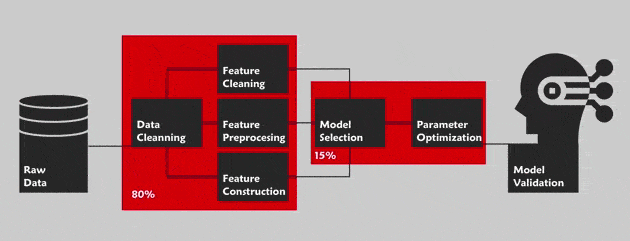
List of open source and payable tools for AutoML
We gathered here another list of open sources and payable tools for Automated Machine Learning.
Open source
- TPOT (Tree-based Pipeline Optimization Tool)
- MLBox
- Auto-Sklearn
- Auto-Keras
- Auto-Pytorch
Payable
- Google Auto-ML
- DataRobot
- PurePredictive
- H2O.ai
- Amazon Lex
Finally, to answer the initial question: “Is AutoML a real thing or not?”. We can’t say that it doesn’t exist, but in my understanding, we can explain “automated” as a loop that contains plenty of methods and processes(cleaning, formatting, tuning parameter, model machine learning, architecture deep learning…) and turns in order to provide the best case scenario for a specific problem.
Today, Automated Machine Learning is in development. On one side it can give efficient results, on another it still needs some improvements. Indeed, it is very limited to supervised learning and face many difficulties relating to unsupervised case and reinforcement learning.
AutoML won’t replace the data scientists
AutoML won’t replace the data scientists, so we do not need to worry colleagues (at least for now). However, we can see it is as a support to Data Scientists and a great way to facilitate this complex field for the non-experts, so they can benefit from the Machine Learning experience.
In addition, for a better illustration, we may consider Kaggle (a competition community of Machine Learning). In fact, humans have always won with models not generated by AutoML tools. As far as I know at least, AutoML didn’t win any contest of data science.
So, is there going to be a day when the pipeline generated by AutoML wins such competitions?
At the end, I hope that it was easy to understand for all of you. I am at your disposal to further discuss and answer your questions in the comments section 😉.














Comments (2)
Your email address is only used by Business & Decision, the controller, to process your request and to send any Business & Decision communication related to your request only. Learn more about managing your data and your rights.
to try Machine Learning and AutoKeras (https://autokeras.com/) for Deep Learning. Finally, to understand both sides.