
The concept of the data lake in conjunction with the trend towards Big Data is a way for businesses to set up a federated data storage platform based on contributions from Big Data technologies. Storage capacity is large and scalable for both structured and unstructured data. Lower total cost of ownership (TCO) than for traditional relational databases.

© EMC
But how can this data lake be combined with a data warehouse that already serves as the real keystone of the business’s acquired holdings of structured data?
Here are four suggestions for cleaning and unifying data holdings by taking an agile and incremental approach.

- The lake
- The mine
- The foundry
- The fort
- Shelving
1. The lake: setting up the data lake
The data lake is a storage area for all external or internal data (unused or only partially used within the business) as yet unproven in terms of both reliability and added value.
Data is thus stored and indexed along the way without transformation:
- If the data is varied and large in volume, it can be hosted and indexed natively on distributed Big Data platforms like Spark or Hadoop.
- If the data are almost exclusively log-like and/or semi-structured, document-oriented NOSQL databases like CouchDB and Mongo DB, key-value stores like RIAK and REDIS and search engines like Elastic Search or Splunk are worth looking at.
- If large volumes of unstructured data are to be handled, search engines with NLP (natural language processing) semantic analysis such as the Apache open source project OPEN NL or publishing solutions such as Attivio, Expert System or Sinequa should be considered. For solutions combining text and image analysis we might suggest IBM Watson (Alchemy API).
- Lastly, if the data lake is expected to evolve in terms of perimeter and variety of data, all of the above can be connected or hybridised.
Setting up a traceability system

avoid your data lake turning into a data swamp
To optimise the maintainability and usability of the data lake, it is advisable to set up a data tracking and traceability system.
This must at least involve the implementation of clear tree views and complete filenames that allow the origin and time of capture of data to be identified quickly. This is a vital condition if the data lake is not to degrade into a data swamp.
2. The mine: transforming and normalising data from the data lake using data preparation tools
Data preparation tools are intended to enforce suitable technical standards of quality on data. The aim here is to exclude badly formed or aberrant data and to identify interactions and overlapping data.
- This work can be greatly simplified if the tool or tools selected offer “recommendation” functions or automatable and re-executable routines.
- To execute conversions quickly using an ELT approach, many solutions offer connectors to Big Data appliances or platforms. However they are still not all capable of being run natively on these platforms in distributed form.
- As this is a rapidly expanding market, I recommend regularly consulting Gartner’s Magic Quadrant or Forrester’s Waves which deal with the topic.
Hosting these results on the same platform
Once cleaned and reworked, the data has to be stored. For a good cost/performance compromise it is recommended that these results should be hosted on the same platform used for the data lake. It is thus vital to retain the data before and after transformation. This means that specific directories need to be created in the data lake. This allows data that has been cleaned to be dissociated from that which has yet to be cleaned.
Lastly, thinking in terms of auditing and monitoring data transformations, the use of data lineage functions is also recommended. These functions are offered either by the data preparation tool or by the data storage platform, where they exist.
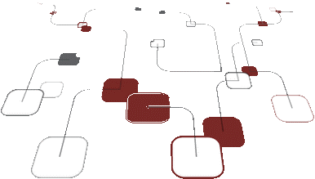
Data lineage, or how to track the data transformation and ingestion cycle in data holdings
3. The foundry: setting up a playground or “datalab” for professionals and data scientists
The playground or datalab is a space exclusively dedicated to experiments and the “functional” cleaning of data.
- It can be physically located on a Spark or Hadoop type distributed processing platform. It can be accessed via specific access rights.
- Upstream, tree structures and shortcuts have already been set up during the data preparation phase to ease the way to analysis.
- It is highly recommended that there should be connectors to the data warehouse and “production” databases to carry out cross-analyses, a rich source of learning.
As in the preceding steps, it is best to set up monitoring for operations already carried out in the datalab. The aim here is to identify and capitalise on what has been done already, but also to identify what still remains to be exploited in the data lake.
4. Fort Knox and its shelving: integrating warehoused data into an agile and incremental approach
The data warehouse – often already an existing building block of an IT system – does not always make it “easy” to integrate new data. When a new stream is added this generally impacts the table structure and even the data warehouse model itself. In order to limit these edge effects, and to avoid compromising existing facilities, it is possible to set up agile approaches to modelling such as a data vault or anchor modelling. The aim is then to:
- Extend the coverage of the data warehouse without degrading existing provision
- Ensure that data is traceable
- Put some of the analyses previously performed in the datalab into production
- Unify and centralise all high added value strategic data on the business and its ecosystem.
This makes it important to find the right balance between the data to be stored in the data lake and that to be stored in the data warehouse. Not all the data from the data lake and the datalab will be suitable for inclusion in the data warehouse (particularly data which is highly volatile). Thus the data lake is intended for use for ad hoc analysis on demand, not production use. Conversely the data warehouse meets recurrent and production needs.
In conclusion, the incremental and scalable design of the data lake and the agile development of the data warehouse are ongoing projects that aim to extend existing decision-making architecture. This should not undermine the main principles on which they are constructed.
In summary
Decision-making in the big data era can be summarised this way:
- Technically speaking, by a wider variety of data handled, by the implementation of execution platforms distributed over all or part of the chain and by a “smart” distribution of data between the data lake and the data warehouse.
- Operationally speaking, by implementing a datalab to learn more about all the business’s data capital with the aim of constant improvement or even a totally disruptive approach to its constituent processes.
- Organisationally speaking by setting up an “agile” unit for centralising and cleaning up data.














Your email address is only used by Business & Decision, the controller, to process your request and to send any Business & Decision communication related to your request only. Learn more about managing your data and your rights.